On Nov. 25 2020, AWS had a serious outage in northern Virginia region which impacted lots of companies, my company included as well no doubt. Specifically, this outage came from Kinesis, but then it across other services like Cognito, CloudWatch etc. This outage caused a serious impact on one of our applications, I would like to give a detail why this happened and what I learned.
What Happened in AWS?
From AWS Service Health Dashboard, the outage started from Kinesis:
9:52 AM PST: The Kinesis Data Streams API is currently impaired in the US-EAST-1 Region. As a result customers are not able to write or read data published to Kinesis streams. CloudWatch metrics and events are also affected, with elevated PutMetricData API error rates and some delayed metrics. While EC2 instances and connectivity remain healthy, some instances are experiencing delayed instance health metrics, but remain in a healthy state. AutoScaling is also experiencing delays in scaling time due to CloudWatch metric delays. For customers affected by this, we recommend manual scaling adjustments to AutoScaling groups.
10:47 AM PST: We continue to work towards recovery of the issue affecting the Kinesis Data Streams API in the US-EAST-1 Region. For Kinesis Data Streams, the issue is affecting the subsystem that is responsible for handling incoming requests. The team has identified the root cause and is working on resolving the issue affecting this subsystem. The issue also affects other services, or parts of these services, that utilize Kinesis Data Streams within their workflows. While features of multiple services are impacted, some services have seen broader impact and service-specific impact details are below.
12:15 PM PST: We continue to work towards recovery of the issue affecting the Kinesis Data Streams API in the US-EAST-1 Region. We also continue to see an improvement in error rates for Kinesis and several affected services, but expect full recovery to still take up to a few hours. The issue continues to also affect other services, or parts of these services, that utilize Kinesis Data Streams within their workflows. While features of multiple services are impacted, some services have seen broader impact and service-specific impact details are below. We continue to work towards full recovery.
What Happened in Our Side?
One of our main application is built based on Kinesis and several our company’s partners are fully depended on this service. Typically, it’s a serverless application and here is the architecture diagram of this application:
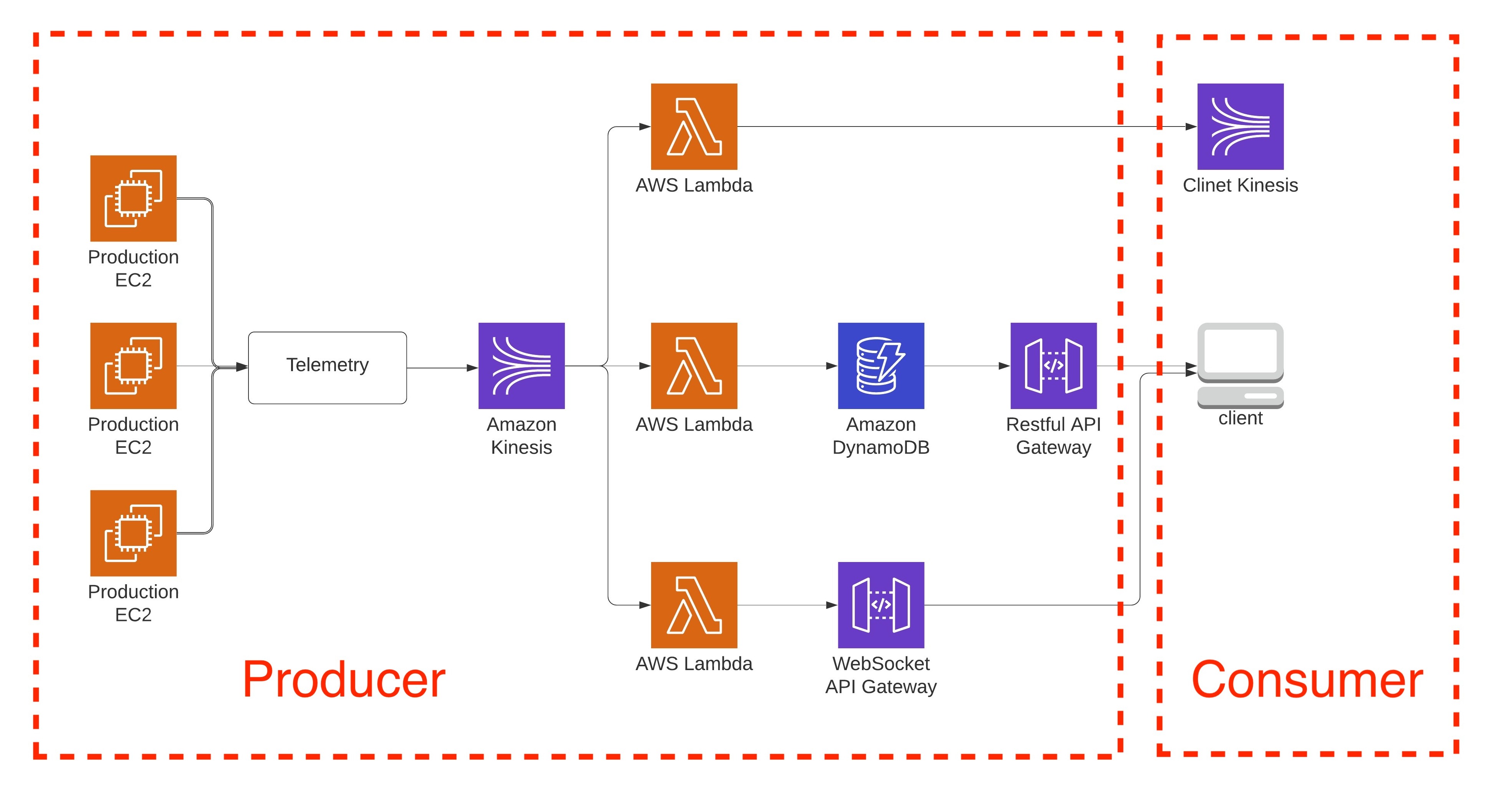 I started to get the first Kinesis alert at around 10:00 AM PST said our lambda functions had a higher read latency from Kinesis. So our client(Consumer) were not able to collect the data from our side. Later on, I got some clients complaints that they were not able to do any data ingestion and analysis due to this outage and asked me if I could do any mitigations. Unfortunately, I could not.
I started to get the first Kinesis alert at around 10:00 AM PST said our lambda functions had a higher read latency from Kinesis. So our client(Consumer) were not able to collect the data from our side. Later on, I got some clients complaints that they were not able to do any data ingestion and analysis due to this outage and asked me if I could do any mitigations. Unfortunately, I could not.
What Challenge I Faced?
There were several challenges I faced at that time:
- I first asked the clients whether they have any back up options since this outage was only on AWS, and we did not have any control on it. Unfortunately, they did not have any back up options. Their work is fully depend on the data self and could not roll back to the previous solution.
- Because our production data all goes to Telemetry broker(our company customized data collector), so I asked Telemetry engineers if they can send the data to a different region Kinesis stream. Unfortunately, since that week was Thanksgiving holiday and all our company changes were on hold, so we could not do that.
- I figured out that I can make a traffic switch if I got a senior management approval, but it could not be done immediately. Worked across different teams in a big Tech company is always a challenge.
Result
Finally, our clients had to shut their system down all day and AWS spent the whole day to recover the Kinesis. Fortunately, the system is back up on the second day.
Takeaways
AWS posted a great article to explain this outage, worth to read: Summary of the Amazon Kinesis Event in the Northern Virginia (US-EAST-1) Region.
Here is what I learned:
- Do not 100% rely on cloud service, you always need to think about the back up options.
- For a complex system, any single point of failure could put the whole system down. This single point can be recovered quickly some time if you have fully controls. But in this outage, I do not have any control on the Telemetry system, so I could not make any change here. Thus, you always need to have a total control of the system you built it up.
- Spend more time on the customers. I was not aware the clients had 100% dependency on our system until this outage happened. So trying to understand the costumers’ real needs is a top priority to build software products.